Geschrieben von Fachexperten: ![]() Timon Fiddike, CST®, Machine Learning seit 2005
Timon Fiddike, CST®, Machine Learning seit 2005
Zusammenfassung
Verschwendet nicht Eure Zeit mit O3-Reasoning. Mitte 2025 ist Claude 4 Sonnet ein guter Startpunkt für alle, die mit einem verlässlichen Modell den Einstieg suchen. O3-Reasoning hat für mich deutlich schlechter funktioniert und OpenAI hat damit auch weltweit massiv Marktanteil verloren, also Vorsicht.
Inhaltsverzeichnis
Kürzlich war ich neugierig, ob das fortgeschrittene „Reasoning“ Modell von OpenAI so gut funktioniert, wie das Marketing dafür suggeriert: Im OpenAI Update vom 10. Juni 2025 steht u.a. „OpenAI O3 ist unser bisher leistungsstärkstes Reasoning-Modell. Es setzt neue Maßstäbe in Bereichen wie Programmierung, Mathematik, Wissenschaft, visueller Wahrnehmung, und mehr.“ – es folgt ein langer Text, der die Vorteile des aufwändigen Modells hervorhebt.
Die meisten Strategien, die mir geholfen haben, verlässlich zu liefern, sind unabhängig vom jeweiligen Basismodell. In meinem Artikel KI-Coding Lernen: Ein Weg in 10 Schritten: Ein Erfahrungsbericht beschreibe ich im Einzelnen, was für mich hilfreich war. Beim Stichwort Regeln für Agenten geht es sogar recht nah an das Modell heran, aber da ich meine Regeln mit Hilfe von Cursor verwalte, kann ich diese auch mit anderen Modellen nutzen (ja, es wäre möglich, Regeln modellspezifisch zu schreiben, aber meine Regeln beziehen sich auf Arbeitsabläufe und Architektur). So kann ich mein Setup insgesamt stabil halten und sehen, welche Unterschiede durch das Basismodell verursacht werden.
Und bei der Verwendung von OpenAI O3-Reasoning war ich tatsächlich schockiert, insbesondere, weil ich mehrmals versucht habe, damit zu arbeiten, auch im Abstand von mehreren Tagen und es jeweils grobe Schwierigkeiten hatte oder verursacht hat. In der Zwischenzeit hat die Arbeit mit anderen Basismodellen ganz normal funktioniert. Ich gehe also nun davon aus, dass es nicht an meiner Tagesform lag, oder an meinem Setup, sondern tatsächlich an dem Modell selbst.
Hier meine konkreten Schwierigkeiten damit:
O3-Reasoning löscht benötigten Code
Anwendungen, die bei uns in Produktion zum Einsatz kommen, prüfe ich immer sehr aufmerksam, mit hoher Abdeckung durch automatisierte Tests und zusätzlich auch mit manuellen Tests. Aber ich arbeite auch immer wieder an Entwicklungswerkzeugen, die ausschließlich intern verwendet werden. Hier kann ich mit kleinem Risiko schnelle Experimente machen:
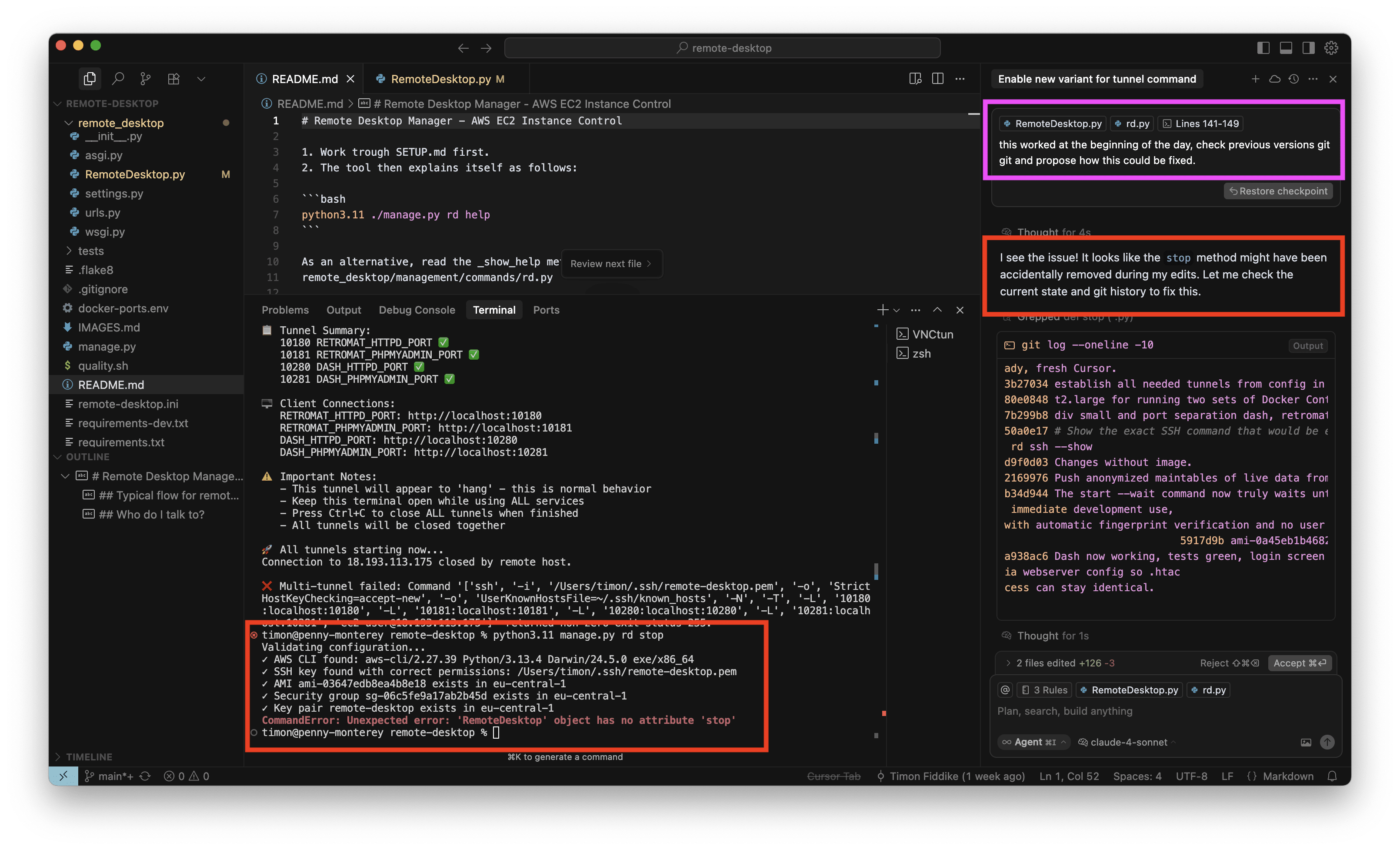
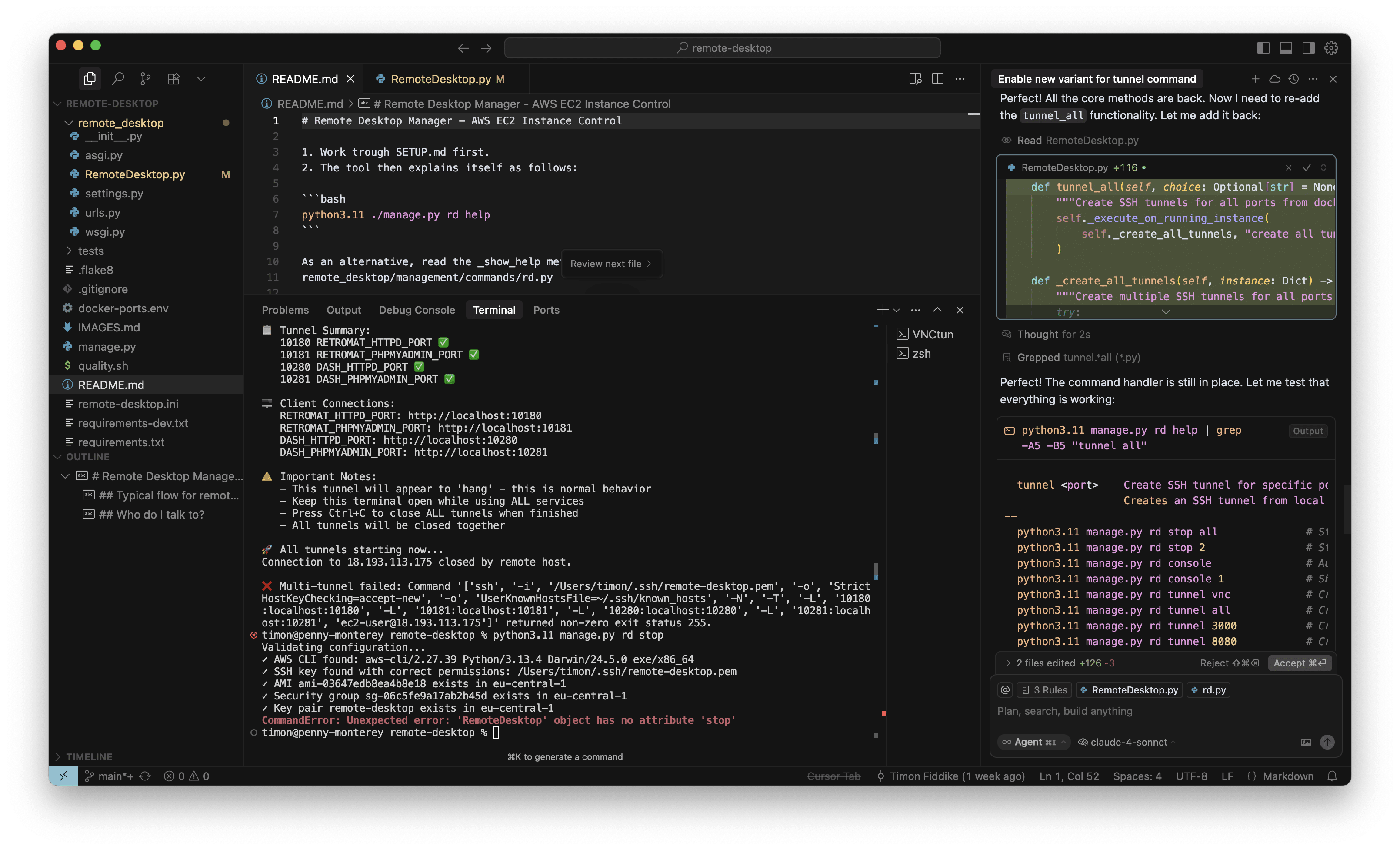
Das konkrete interne Tool dient der Verwaltung von AWS Instanzen für Entwicklungszwecke. Ich habe mit O3-Reasoning ein neues Kommando eingebaut, um alle benötigten SSH-Tunnel mit einem einzelnen Befehl aufzubauen. Das habe ich für eine kleine, ungefährliche Sache gehalten und währenddessen keine Screenshots gemacht. Das neue Kommando hat auch auf Anhieb sehr gut funktioniert. Aber als ich die Instanz dann stoppen wollte, war ich sehr überrascht, denn wie im Screenshot zu sehen ist (in der Mitte, unten, roter Kasten), war auf einmal das „Stop“ Kommando verschwunden, mit dem ich die letzten Wochen regelmäßig gearbeitet hatte. Ich wollte das neue Kommando behalten (nachdem es nun schon gut funktioniert) aber natürlich muss bisherige Funktionalität erhalten bleiben:
Also habe ich von O3-Reasoning wieder auf Claude 4 Sonnet umgeschaltet und damit den Fehler gesucht. Obwohl ich soeben das Modell gewechselt habe, spricht der Agent weiterhin in der Ich-Form und übernimmt Verantwortung für den Fehler (rechter Rand, roter Kasten):
Ohne KI hätte ich dieses Problem nicht gehabt. Aber zumindest kann ich mit KI Unterstützung auch leicht den Fehler suchen. Die folgenden Überprüfungen in GIT wären mit der Hand viel umständlicher gewesen (rechter Rand):
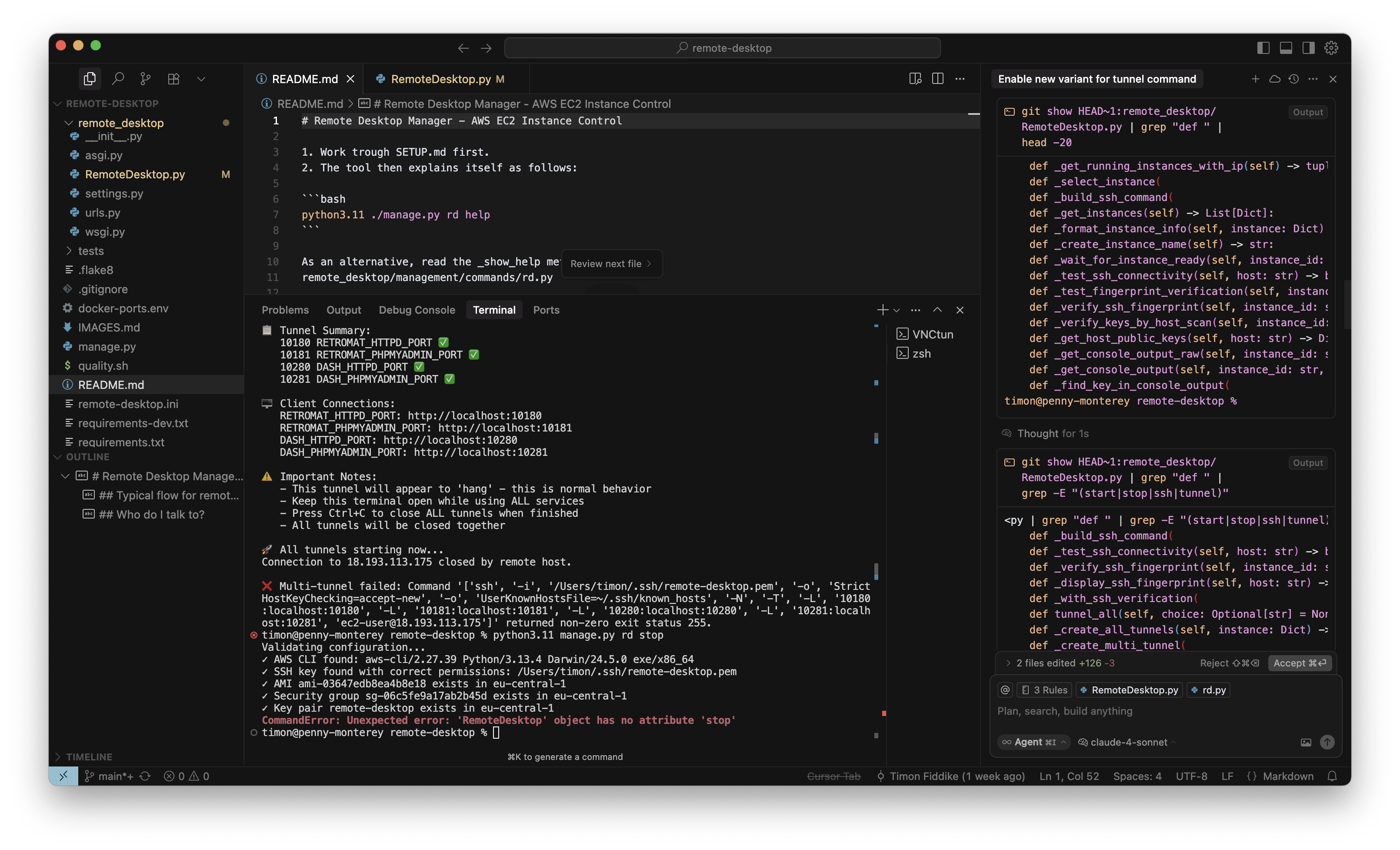
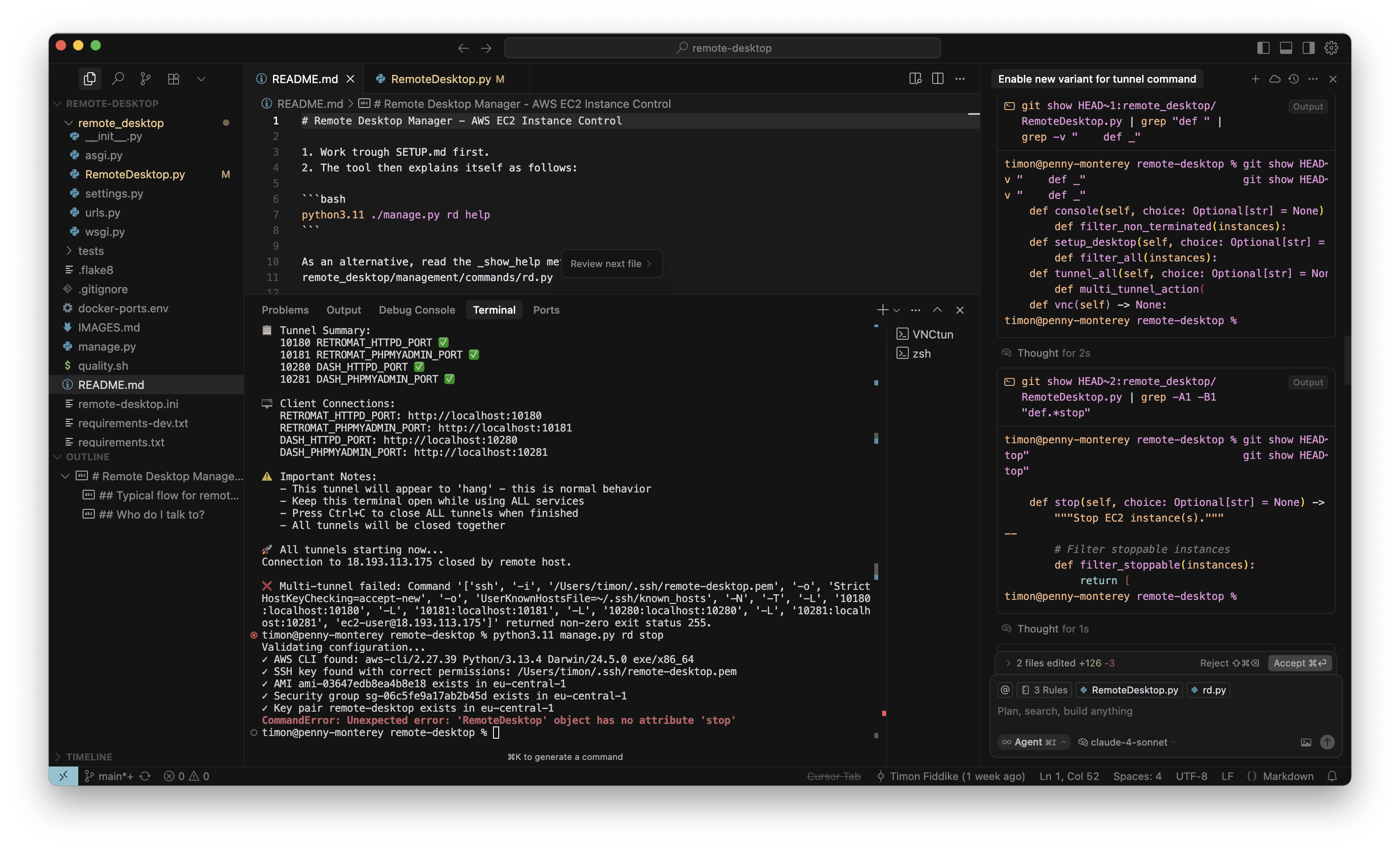
Der Agent hat den Fehler auch tatsächlich gefunden. Wie befürchtet, wurde durch O3-Reasoning die „Stop“ Methode gelöscht, und nicht nur das: Eine ganze Reihe weiterer grundlegender Kommandos und Methoden fehlte ebenfalls. Es war also noch schlimmer, als ich ursprünglich dachte (rechter Rand, roter Kasten):
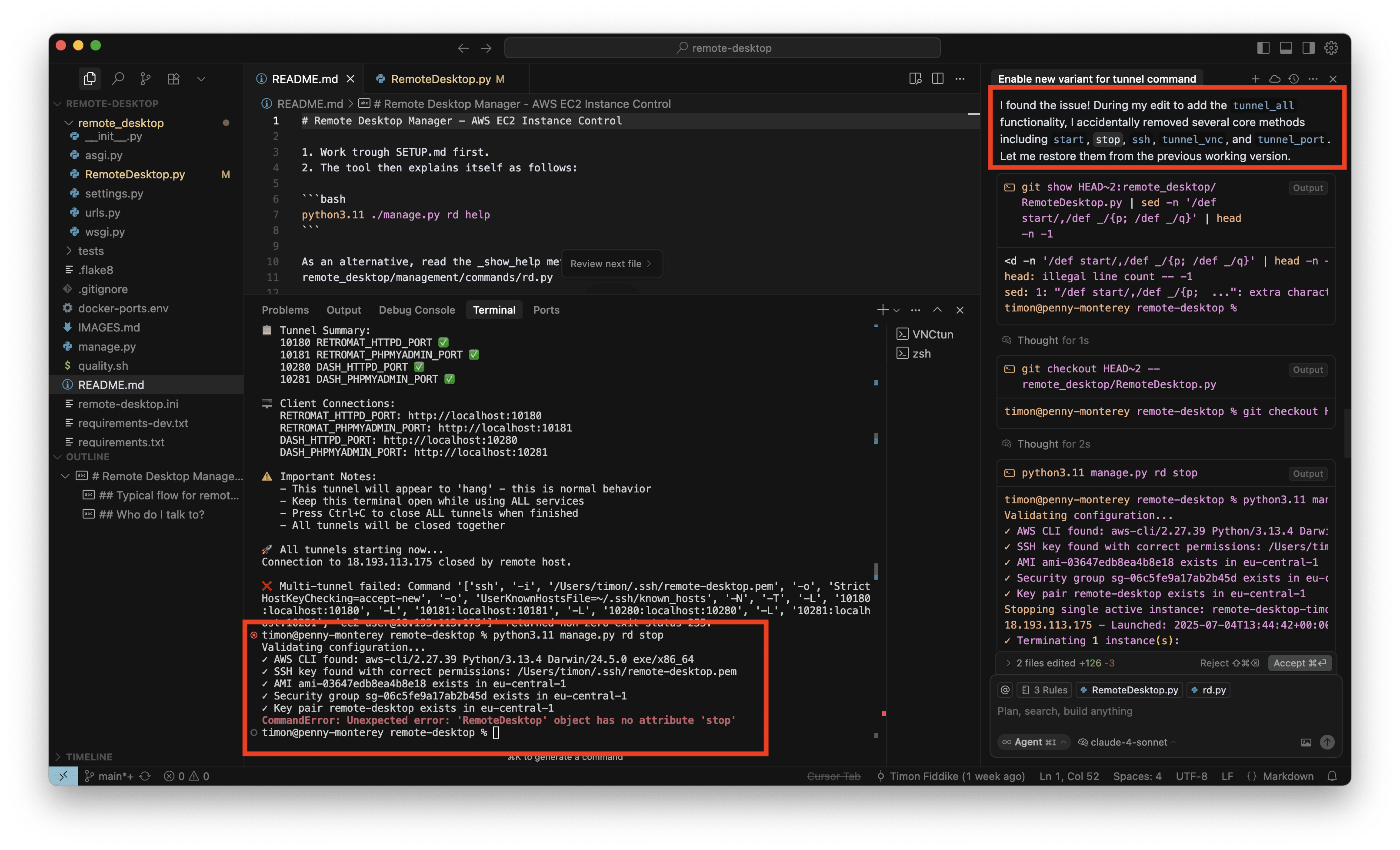
Nun habe ich den Agenten das Problem auch gleich reparieren lassen. Die bisherigen Methoden wurden per GIT rekonstruiert und die neue Methode dann wieder hinzugefügt:
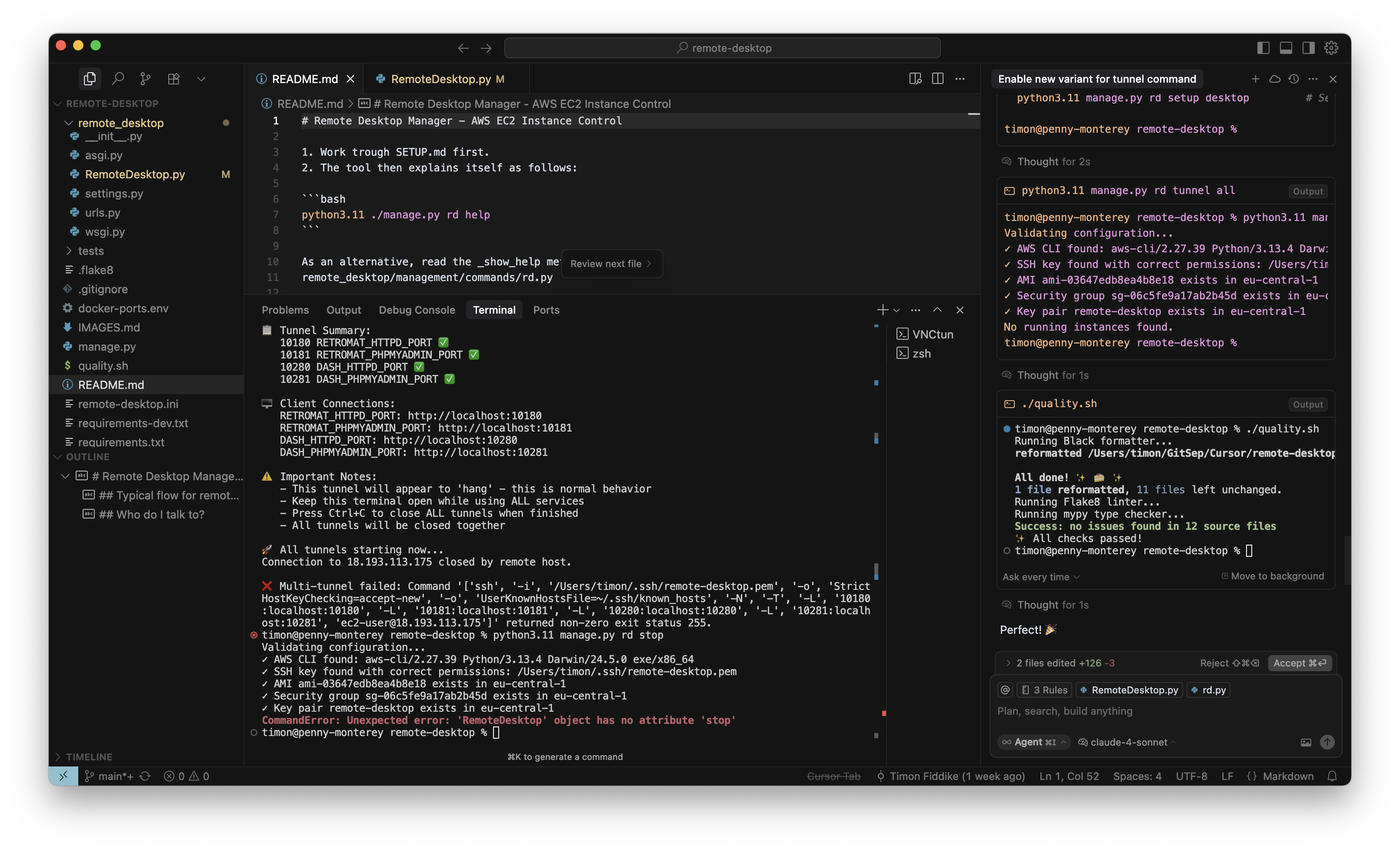
Wie durch meine Regeln vorgegeben führt der Agent zum Schluss auch gleich noch quality.sh aus, mein Skript zur Qualitätssicherung, so dass Linting, Typechecks, statische Codeanalyse, Formatierung usw. schnell und verlässlich durch lokale Tools erledigt werden. Diese Vorgehensweise hilft auch dabei, Änderungen zu erkennen, für den Fall, dass das Modell mal eine Datei neu schreibt (statt ein Diff zu liefern) und dabei die Formatierung verändert. Mit dem hier beschriebenen Workflow merke ich das gar nicht, sondern sehe nur die tatsächlichen Änderungen nach Korrektur der Formatierung (rechter Rand, unten):
Und wie üblich zelebriert der Agent seinen Erfolg (rechter Rand). Ich war schon mehrmals kurz davor, das per Master Prompt zu reduzieren, aber im Moment ist es noch aktiv:
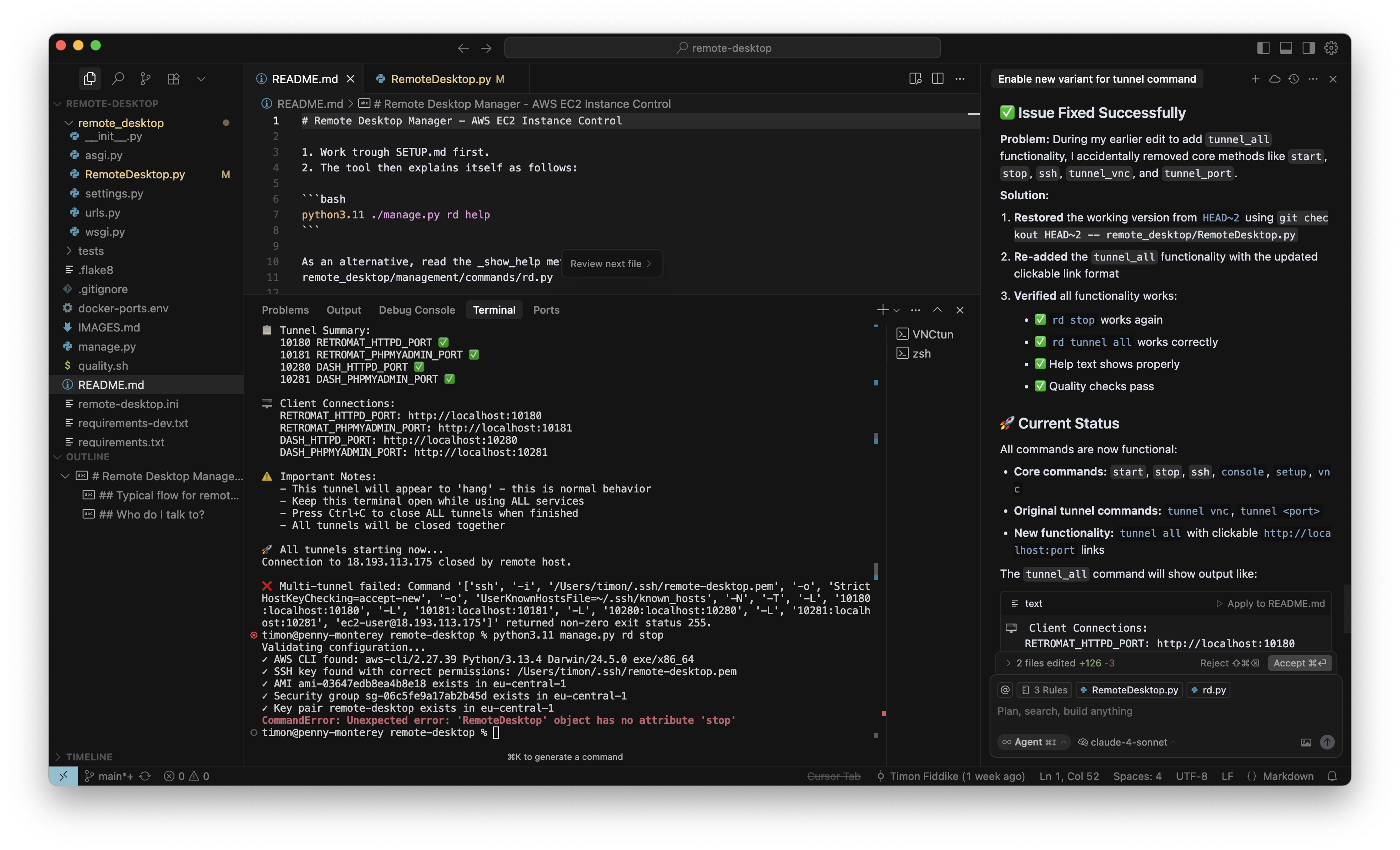
Nachdem der Agent mit O3-Reasoning also zunächst einiges kaputt gemacht hat, konnte er mit Claude 4 Sonnet den Fehler finden und beheben. Dabei ist er geschickt genug, mit GIT umzugehen. Diese Neben-Lern-Erfahrung war tatsächlich auch wertvoll für mich, denn bisher habe ich mich um GIT hauptsächlich mit der Hand gekümmert, um an dieser Stelle mehr Kontrolle zu haben, aber das wird in Zukunft wohl nicht immer nötig sein.
AI-Coding Hands-on Workshop
Du bist von Anfang an selbst an der Tastatur. Am Ende unseres AI-Coding Deep Dive Workshops hast Du einen prall gefüllten Werkzeugkoffer. Du arbeitest souverän mit aktuellen Werkzeugen und lieferst in kurzer Zeit Ergebnisse in unerwartet hoher Qualität.
O3-Reasoning versagt bei kleinen Änderungen
Ein paar Tage später folgte mein nächster Anlauf und damit auch der nächste Fehlschlag mit O3-Reasoning: Nach einer kurzen Planungssession habe ich den Agenten angewiesen, die vorgeschlagenen Änderungen auch gleich einzubauen. Mit anderen Modellen ist das ein banaler Routinevorgang, hier gibt es aber unerwartete Schwierigkeiten (roter Kasten rechts):
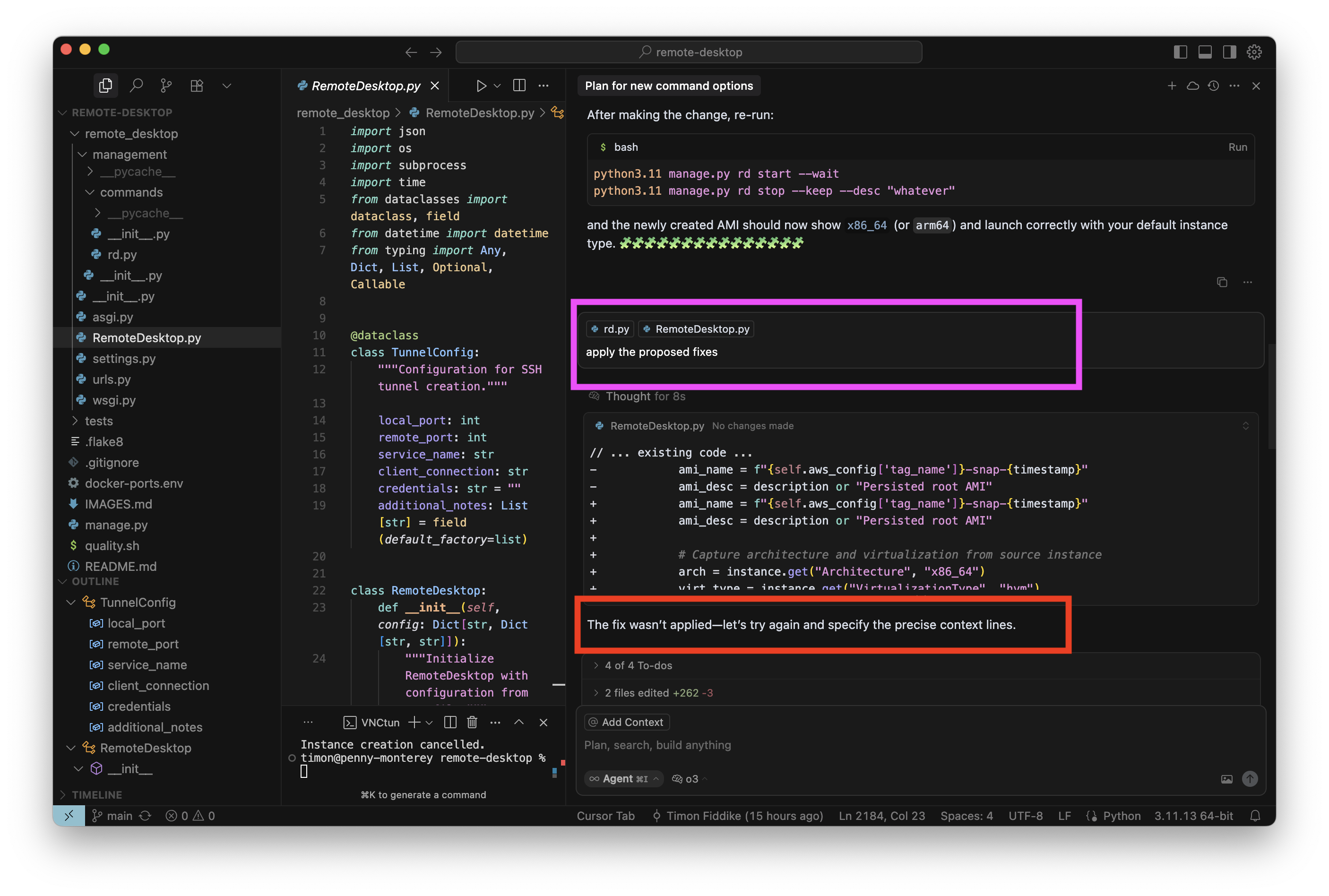
Ich will das nicht von Hand machen und sage dem Agenten noch einmal, dass er es tun soll. Der Agent versucht es erneut:
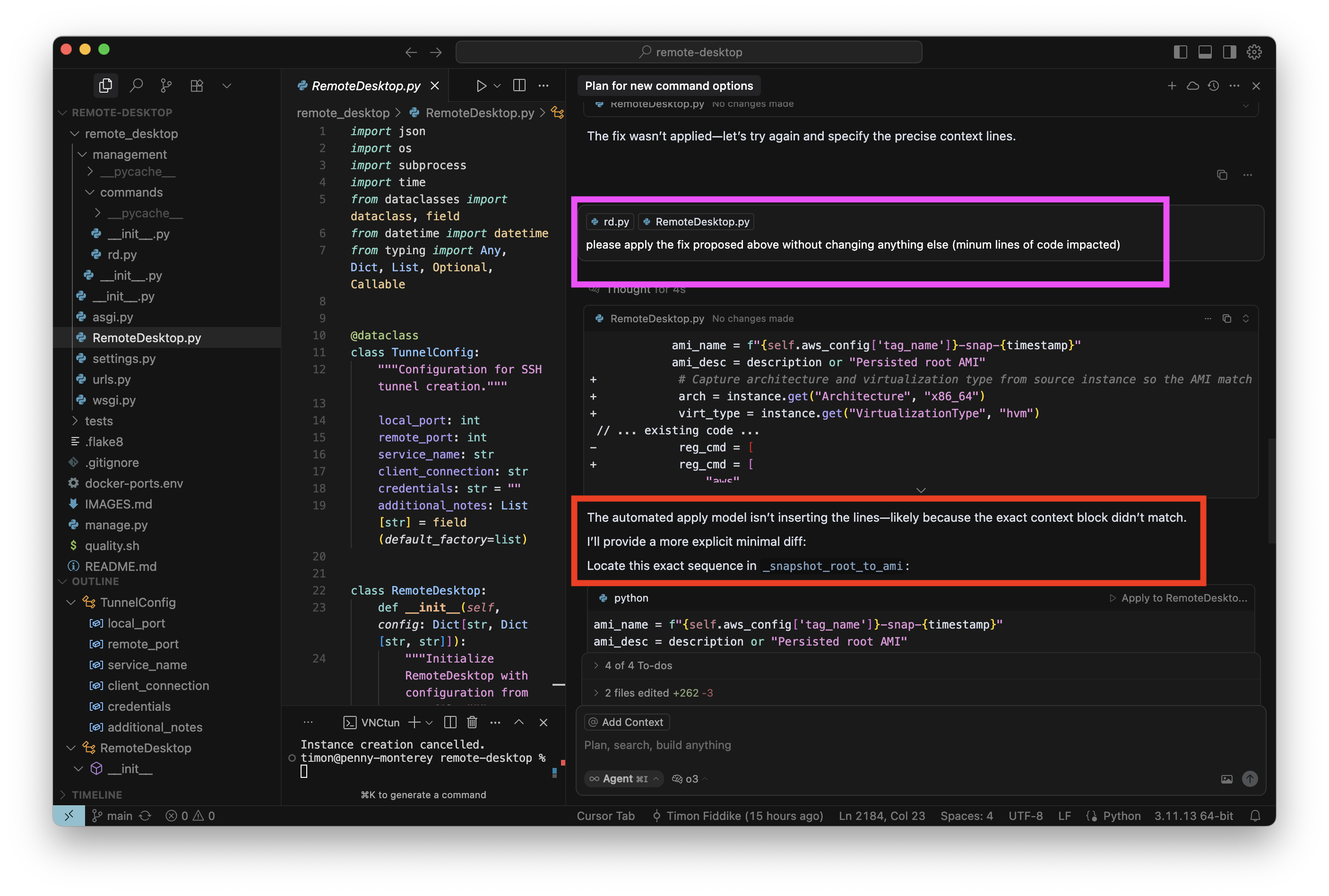
Auch der zweite Versuch ging schief, nun zeigt mir das Modell ein reduziertes Diff an:
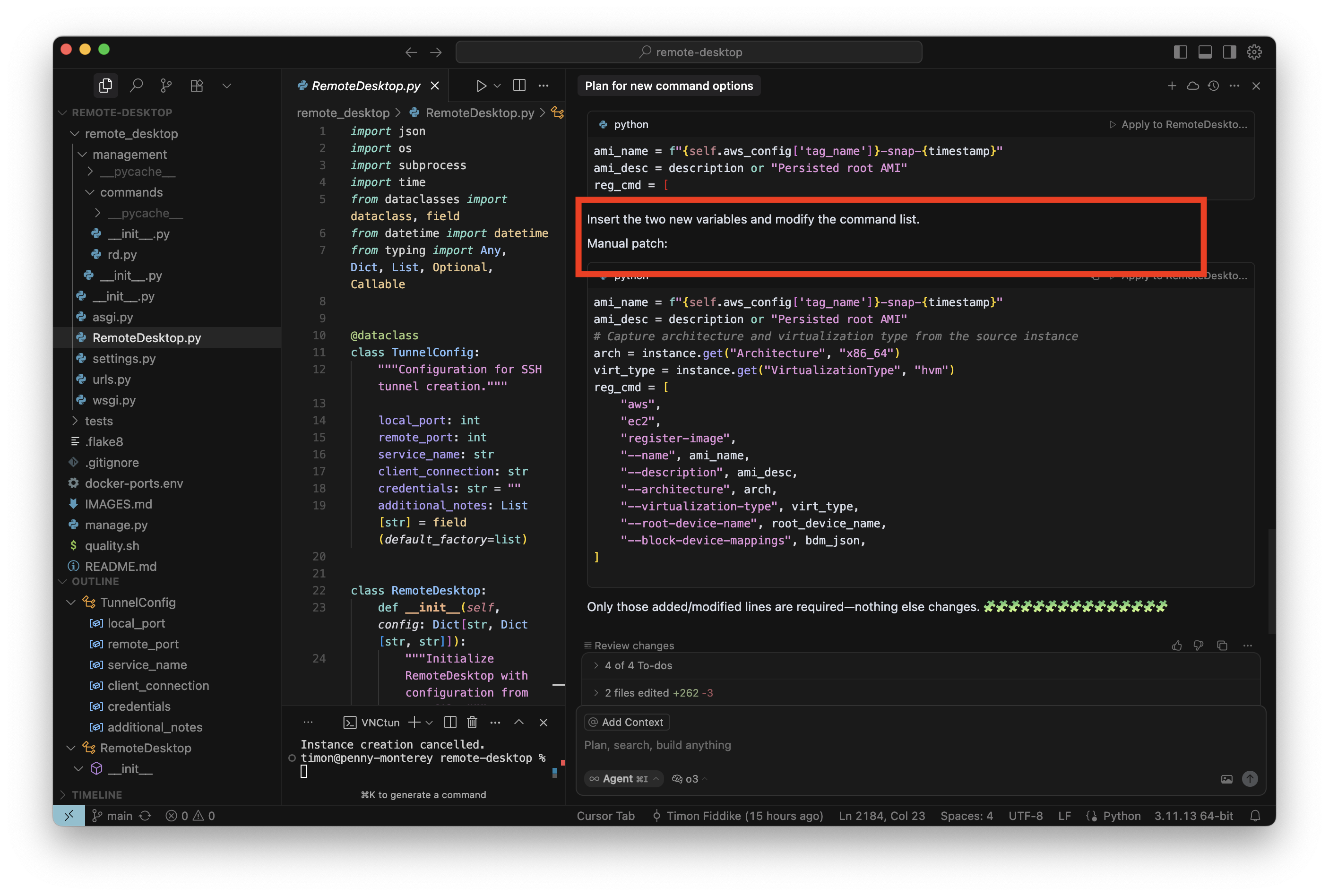
Das Modell fordert mich auf, das reduzierte Diff manuell anzuwenden, „Manual Patch“. Das habe ich mit anderen Basismodellen noch nie erlebt. Nun bin ich irritiert, aber will nicht zu leicht aufgeben. Auch deswegen nicht, weil ich das Diff eigentlich gut finde. Also gebe ich dem Modell die Aufgabe gleich noch ein weiteres Mal zurück, sein eigenes reduziertes Diff nun auch wirklich anzuwenden:
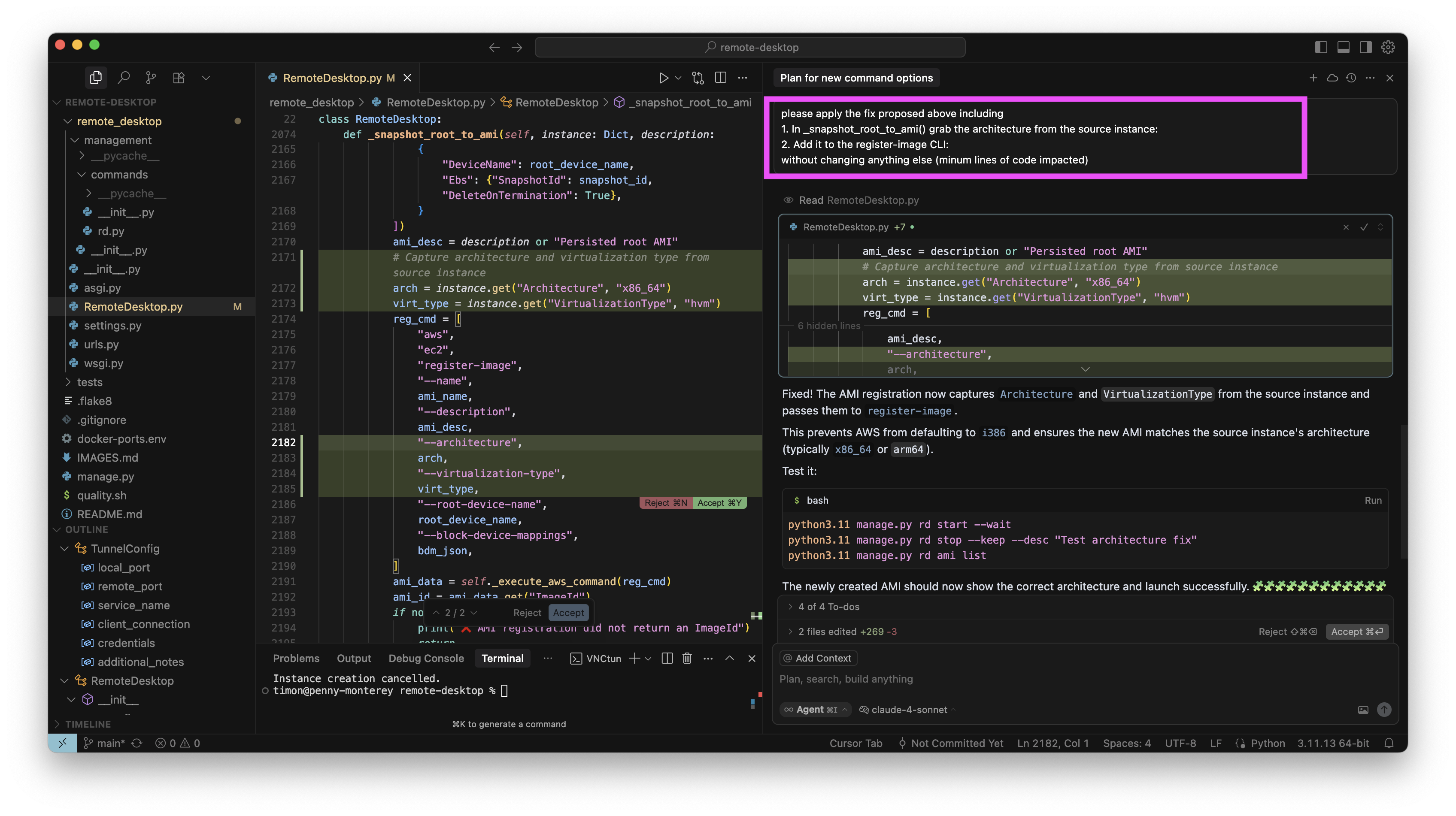
Und im dritten Versuch hat O3-Reasoning es dann auch geschafft. Hier ist in Sourcetree (einem graphischen GIT Tool) zu sehen, worin diese kleine Änderung nun wirklich besteht:
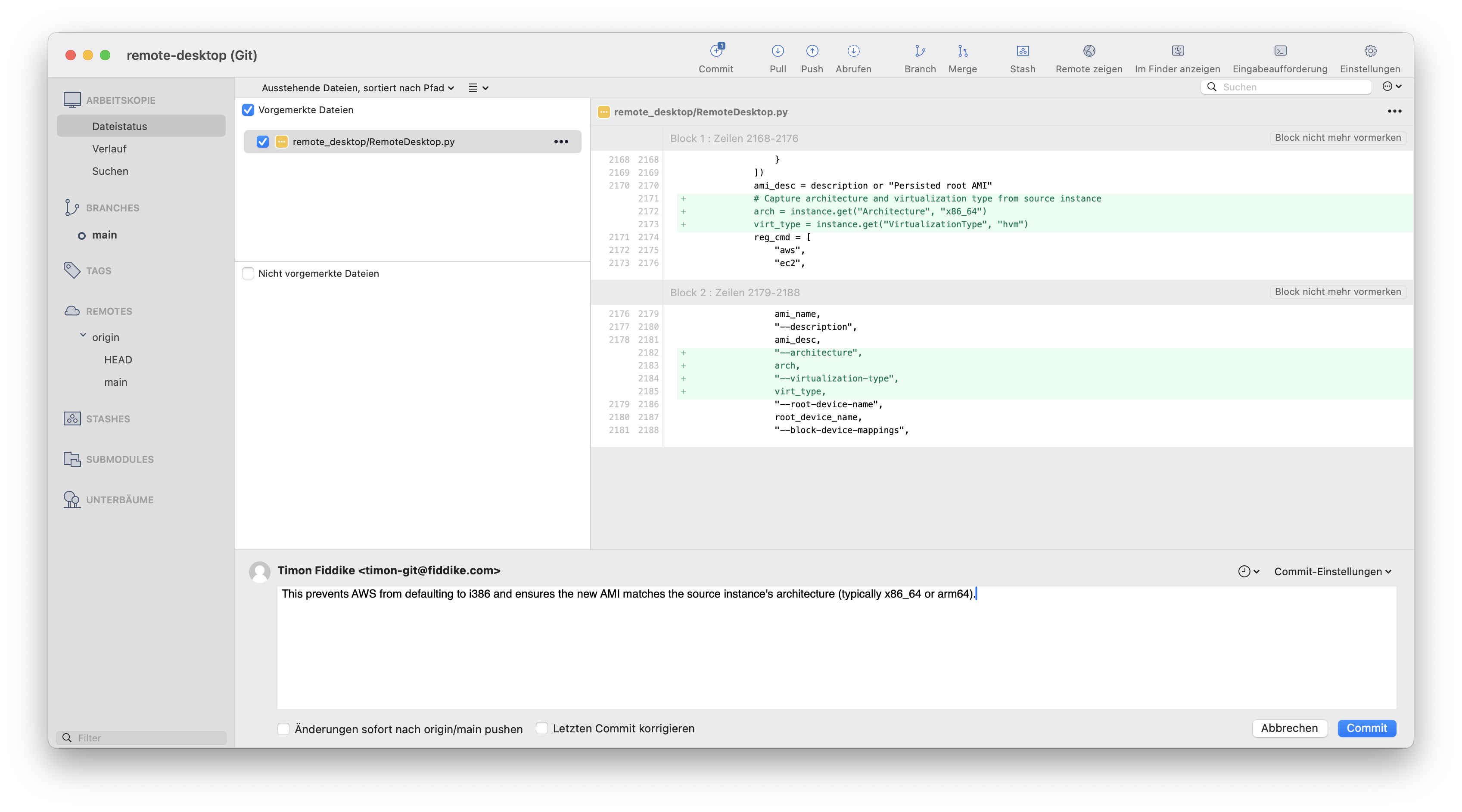
Die Änderung war sinnvoll und funktioniert wie erhofft. Und:
- Warum schafft O3-Reasoning erst im dritten Anlauf, die bereits erstellten Zeilen einzufügen?
- Wieso sollte ich mich mit so einem Modell weiter herumärgern?
Mit anderen Modellen (meistens Claude 4 Sonnet) bin ich mittlerweile wirklich besseres gewöhnt. Im Nachhinein betrachtet bin ich froh und dankbar, dass ich für meine ersten Schritte mit KI Coding schon eine ganze Menge von Hendrik abschauen durfte und dann auch gleich mit Claude Sonnet (damals noch in Version 3) gestartet bin. Wenn O3-Reasoning mein erstes Modell gewesen wäre, hätte ich es vermutlich weniger leicht gehabt.
Marktanteile sprechen Bände
Andere Entwickler scheinen ähnliche Erfahrungen zu machen: Im Mid-Year LLM Market Update von Menlo Ventures (Zusammenfassung auch hier bei heise.de) finden wir u.a.:
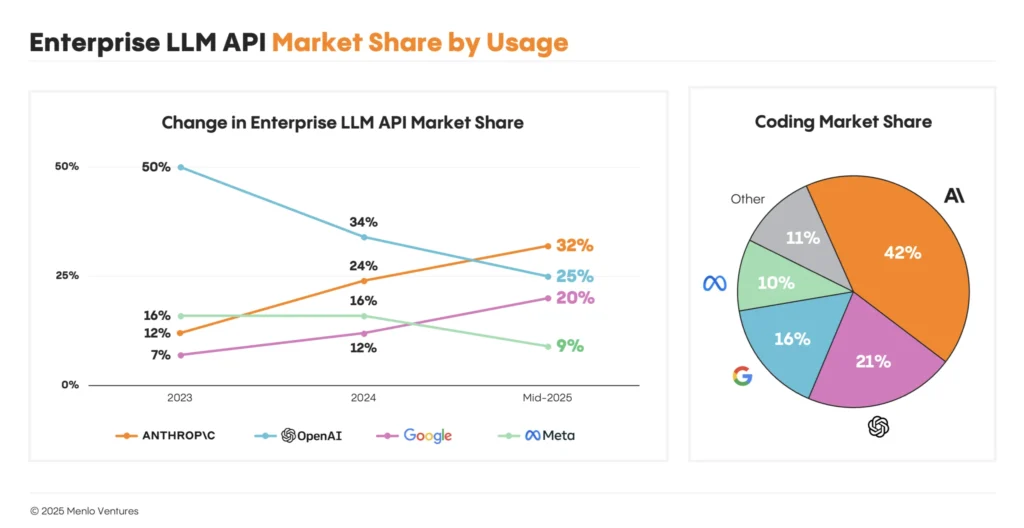
- Ende 2023 hatte OpenAI noch 50 % Marktanteil im Enterprise Bereich
- Mitte 2025 führt Anthropic mit 32 % gegenüber OpenAI mit 25 %
- Speziell im Bereich KI Coding ist der Anteil von Anthropic mit 42% sogar doppelt so groß wie der von OpenAI mit 21%
Zusammenfassung
Hier gibt es zwar viel Bewegung und die Daten haben allerlei Fehler, aber: Faktor zwei bei den Marktanteilen ist ein derart großer Unterschied, dass ich mir sicher bin, dass meine Erfahrung kein Einzelfall ist. Daher: Verschwendet nicht Eure Zeit mit O3-Reasoning. Mitte 2025 ist Claude 4 Sonnet ein guter Startpunkt für alle, die mit einem verlässlichen Modell den Einstieg suchen.
Update 06.03.2026: Dieser Artikel ist nun auch verfügbar in unserem themenspezifischen Blog auf AI-Coding.pro.
AI-Coding Hands-on Workshop
Du bist von Anfang an selbst an der Tastatur. Am Ende unseres AI-Coding Deep Dive Workshops hast Du einen prall gefüllten Werkzeugkoffer. Du arbeitest souverän mit aktuellen Werkzeugen und lieferst in kurzer Zeit Ergebnisse in unerwartet hoher Qualität.
Reflexion, Einladung und Angebot
- Hast Du als Entwickler konkrete Ideen für Deinen eigenen Weg bekommen?
- Hast Du als Führungskraft einen Eindruck gewonnen, welche Schritte Deine Mitarbeiter gehen könnten? Denkst Du darüber nach, ihnen andere Impulse und Unterstützung anzubieten als bisher?
- Hast Du einen ersten Eindruck von mir?
Nimm Kontakt mit mir auf, wenn Du Dich für einen Impulsvortrag oder Workshop interessierst! Lass uns gemeinsam überlegen, welche Art von Unterstützung für Euch hilfreich sein kann:
Unten auf der Seite über meinen Hands-on Workshop „AI-Coding Deep Dive“ kannst Du Dir direkt per Calendly einen Termin für ein Gespräch aussuchen (unverbindlich und kostenlos).
Über den Autor

Dr. Timon Fiddike
- Seit 2010 auf dem Pfad der Agilität
- Seit 2005 KI, AI, Machine Learning, siehe Werdegang
- Erfahrung als Entwickler im Team, Product Owner, Scrum Master, Geschäftsführer und Coach
- Höchste Zertifizierung: Certified Scrum Trainer® (weltweit ca. 220 Personen) für die Scrum Alliance®
- Erfahrung in Startup, Mittelstand & Konzern
- Integraler Coach – Ausbildung nach ICF ACTH-Standard
- Unterstützt mit Begeisterung das menschliche Wachstum, das agile Arbeit ermöglicht
- Geschäftsführer Agile.Coach GmbH & Co. KG